DearOneの小林と申します。DearOneのグロースマーケティング部で、主に「Hightouch」の営業や導入の支援を行っています。最近出雲大社にお参りしてきたので過去最高のご利益が今この身に宿っています。
DearOneは、Hightouchの日本唯一の販売代理店としてHightouch社から様々な情報共有を受けています。その情報を皆様にできるだけ早く、日本語でわかりやすく伝えていきたいと思います。
今回は、Hightouchが様々なマーケティングツールとデータ連携を行う際に、データの差分を自動更新する仕組みやその効果についてご紹介いたします。
Hightouchのデータ連携の仕組み
まず始めに、Hightouchのデータ連携自体の仕組みについてお話しします。
HightouchはリバースETLというカテゴリに分類されているツールです。リバースETLは「DWHなどのデータが集約されたシステムから、データを様々な外部のツールへ連携する工程」を指します。
ETL/ELTが主にデータ基盤へデータを連携する際の工程なので、その逆という意味で「リバース」ETLと呼ばれています。
HightouchはリバースETL領域において、データの連携元(DWH)と連携先(広告やMAツールなど)をつなぐ役割を担うパイプのようなソリューションになります。
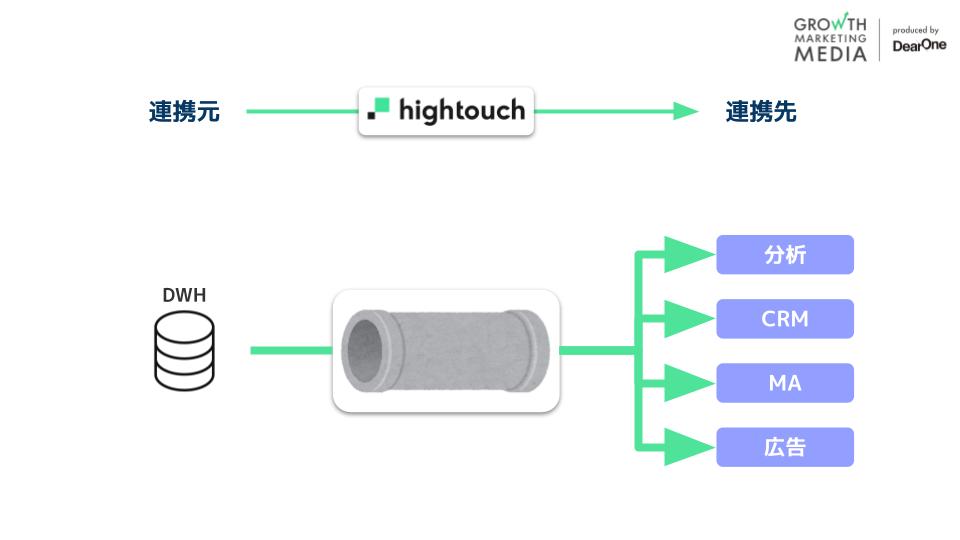
Hightouchの特徴の大きな特徴は、Hightouch内にデータを保持しない点にあります。連携するデータは全て連携元のDWHにあるデータで、Hightouchはそのデータを参照しに行き、連携先へAPIなどを通じて連携する部分を担っています。
これにより、ストレージのコストやセキュリティのリスクを抑えることができます。
Hightouchのデータ差分更新
ここから、本題に入っていくのですが、データ連携を行う際、Hightouchでは前回の連携からデータの差分のみを抽出し連携する「差分更新」が可能です。これにより、変更されたデータだけを更新することで、手間を省き、リアルタイムに近いデータ連携を行うことができます。
実際のマーケティングでは、以下のような施策を行う際、データの差分を連携することが必要になります。
- 「直近◯日以内に購入を行ったユーザー」のような更新が必要なユーザーへのターゲティング
- 特定のユーザー行動をトリガーにしたシナリオ施策
- 値が更新されるような動的なユーザー属性を使ったターゲティング
これらは、より細かいパーソナライズの実施においては不可欠な要件になっています。また、差分が更新されたデータを連携するには、データパイプラインの構築が必要となるため、技術的なハードルが高く多くのリソースを必要としてしまいます。
このような背景から、Hightouchのようなソリューションが今注目を浴びています。
データ差分更新の仕組み
Hightouchのデータ差分更新では、差分を抽出するために「変更データキャプチャ」(英語でChange data capture(CDC))という作業を行います。
Hightouchでは、この変更データキャプチャにおいて、以下の2つを用いて差分の抽出を行います。
- 前回連携されたデータ(前回時点の差分内容)の記録
- 連携実行のタイミングで得られた最新の連携元データ
1は、Hightouchのインフラ側で一時的に保持され、次回の差分更新の際に使われます。
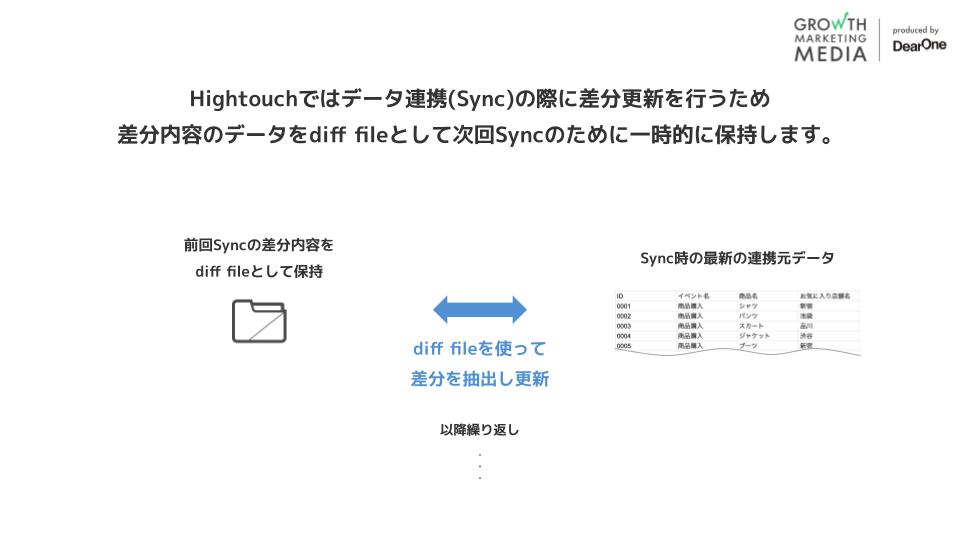
このdiff fileに含まれるデータは実データとは異なるものとなります。また、差分の抽出にあたり、Hightouchでは行ごとのPrimary keyを参照するため、差分更新の際にPrimary keyを連携元データに含める必要があります。
少し専門的な話になりますが、Hightouchでは変更データキャプチャの中でも「difference-based CDC」と呼ばれる手法を採用しており、多くのETLツールで採用されている変更データキャプチャの手法とは異なる方法で行っています。
データ差分更新の流れ
Hightouchでデータの差分を更新し連携が行われる際の、具体的な流れを説明します。
全体の流れは、以下の通りです。
- Hightouch上で設定またはHightouchに共有したデータモデリングに基づいて、クエリを実行(連携元システムでのコンピューティング)
- クエリの結果と差分ファイルを用いて変更データキャプチャを実行(Hightouchインフラでのコンピューティング)
- 差分ファイルをHightouch側のインフラに保存(Hightouchインフラでのストレージ)
- 差分内容を連携先へ連携
データモデリングについてはこちらの記事などで詳細に紹介しています。
関連記事:Hightouchを使ってデータウェアハウス(DWH)のデータを、SQL文を1行も書かずにセグメント化して送信してみた
関連記事:【Hightouch活用事例】dbt連携でデータパイプライン構築・運用を効率化
冒頭で、Hightouchではデータを保持しないと説明しましたが、データ連携に関わるリソースはHightouchが提供するインフラが使われます。
ただし、HightouchのBusiness planをご契約いただくことで、オプション機能として使用するリソースを自社のものに変更することが可能になります。(Hightouchでは、無料で使えるStarter planとビジネス利用向けのBusiness planを提供しています。)
企業によっては、
- データ連携のパフォーマンスを上げる/調節するために自社が利用するリソース(連携元のDWHなどのシステム)を使いたい
- セキュリティ面で、差分ファイル(diff file)のストレージも自社が利用するストレージサービスで行いたい
という場合があると思います。この機能により、データ連携で使われるリソースのほとんど全てを自分たちでコントロールすることができ、より自由に、より安全にご利用いただくことができます。
製品サイトでHightouchの機能を詳しく知りたい方は、以下からご確認ください。
>>Hightouchの資料請求はこちら
>>無料プランやお見積もりなどのご相談はこちら
Hightouch無料プランのご紹介
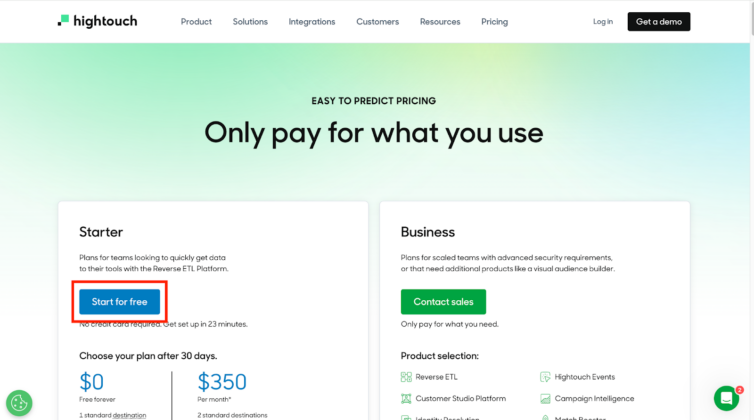
Hightouchでは無料プランを提供しており、リバースETL機能をこのプラン内でお試しいただくことが可能です。無料プランは下記のリンクから数分でご利用開始いただくことが可能で、お支払情報の入力などは必要ありません。
ご興味がありましたらぜひお試しください。(リンク先ページの”Start for free”から)
最後に
データの差分更新が自動でできるデータパイプラインの構築や運用には、たくさんの工数やリソースが必要となり、また技術的な難易度も高い場合があります。また、それぞれの連携先とのデータ連携の仕組みを都度構築するには、毎回エンジニアへの依頼が必要となり、実際にデータが連携されるまでに時間がかかってしまいます。
データ連携のソリューションとして、Hightouchを導入することでさまざまな課題を解決することが可能となります。今後、データ連携の効率化をお考えの方は、ぜひ選択肢の一つとしてご検討ください。
今後も、皆様に刺激や気づきをお届けできる記事や情報を発信してまいりたいと思っております。
最後までお読みいただき、誠にありがとうございました。この記事が皆様のお役に立てれば幸いです。
